대형 언어 모델(LLM)의 급속한 발전과 함께 AI 기반 검색이 전통적인 검색 엔진의 자리를 빠르게 잠식하고 있습니다. 그러나 생성형 검색 엔진이 제시하는 정보 출처의 신뢰성과 일관성에 대한 우려가 학계에서 본격적으로 제기됐습니다. 미국 뉴저지 공대(New Jersey Institute of Technology) 연구진이 1만 4,212건의 검색 쿼리를 분석한 결과(How Generative AI Disrupts Search: An Empirical Study of Google Search, Gemini, and AI Overviews), 생성형 검색은 전통적 검색과 출처가 크게 다를 뿐 아니라 정치·건강 등 민감한 고위험 쿼리에서 신뢰도가 낮은 출처에 의존하거나 특정 입장을 취하는 경향을 보이는 것으로 나타났습니다.
연구 배경: 검색 엔진의 지각변동
사용자들이 챗GPT 등 AI 챗봇을 전통적인 검색 엔진의 대안으로 활용하기 시작하면서, 구글을 비롯한 기존 검색 엔진들도 LLM 기능을 검색 서비스에 통합하기 시작했습니다. 특히 구글은 AI 오버뷰(AIO)를 기본 설정으로 전통적인 검색 결과 페이지(SERP) 상단에 배치하고 있습니다. 사용자가 AI 챗봇을 선택적으로 사용하는 것과 달리, AIO는 사용자의 별도 선택 없이 자동으로 노출된다는 점에서 파급력이 더 크다는 평가입니다.
생성형 검색 엔진은 사용자의 쿼리에 응답해 관련 출처를 검색하고 해당 내용의 요약문을 생성하는 AI 기반 시스템을 가리킵니다. 이러한 시스템은 사용자에게 편의성을 제공하며 급속히 보급되고 있지만, 생성형 검색이 제시하는 출처가 전통적 검색과 어떻게 다른지, 그 차이가 사용자와 웹사이트에 어떤 함의를 갖는지는 여전히 불분명한 상태였습니다.
웹사이트 운영자 입장에서도 생성형 검색은 중요한 변수입니다. 사용자들이 생성된 요약문에서 직접 정보를 얻게 되면서 전통적 검색 결과 목록에 있는 출처로의 트래픽이 감소할 것이라는 우려가 커지고 있기 때문입니다. 역사적으로 웹사이트들은 검색엔진 최적화(SEO) 서비스를 통해 전통적 검색 결과에서의 순위를 높여 트래픽과 광고 수익을 확보해왔습니다. 최근에는 생성형 검색 결과에서 인용 출처로 등장하는 빈도를 높이기 위한 생성형 엔진 최적화(GEO) 서비스도 등장했지만, 그 효과에 대해서는 여전히 논란이 있습니다.
연구 방법: 1만 4,000건 쿼리의 대규모 비교 분석
연구진은 전통적 검색 엔진과 생성형 검색 엔진이 제시하는 출처를 대규모로 비교 분석했습니다. 이를 위해 11,500건의 쿼리로 구성된 벤치마크 데이터셋을 구축했으며, 다양한 주제·사용자 의도·구문 변형을 포괄하는 두 개의 시의성 쿼리셋도 추가했습니다. SerpAPI와 제미나이(Gemini) API를 활용해 구글 검색(전통적 SERP), AIO, 제미나이 2.5 플래시(Flash)의 검색 결과를 수집했습니다.
벤치마크 쿼리셋은 아래 표와 같이 9개 카테고리로 구성됐습니다.
| 데이터셋 | 쿼리 수 | 예시 |
|---|---|---|
| ORCAS | 5,000 | public aid office locations |
| Amazon Retail | 500 | star lamp projector galaxy |
| Amazon Retail-Comp | 500 | Compare star lamp projector galaxy vs aurora projector |
| Amazon Retail-Q | 500 | What is the best star lamp projector for a small room? |
| Debate | 1,000 | Should LGBT rights be protected by law? |
| ELI5 | 1,000 | What determines if a phosphorylated protein is on or off? |
| Localized | 1,000 | free rabies shot near Alicante, Spain |
| NQ | 1,000 | when was the first cell phone call made |
| NQ Keywords | 1,000 | first cell phone call |
| 합계 | 11,500 |
출처 간 차이를 수치화하기 위해 자카드 유사도(Jaccard similarity)와 순위 편향 중첩(RBO)을 사용했습니다. 자카드 유사도는 두 검색 엔진이 공통으로 검색한 출처의 비율을 0에서 1 사이의 값으로 나타내며, RBO는 상위 순위에 더 높은 가중치를 부여해 순위까지 고려한 유사도를 측정합니다. 모든 벤치마크 쿼리에 대한 SERP, AIO, 제미나이의 응답은 2025년 12월 7~8일에 동일한 조건에서 수집됐습니다.
주요 발견 1: AIO는 전체 쿼리의 절반 이상에서 생성
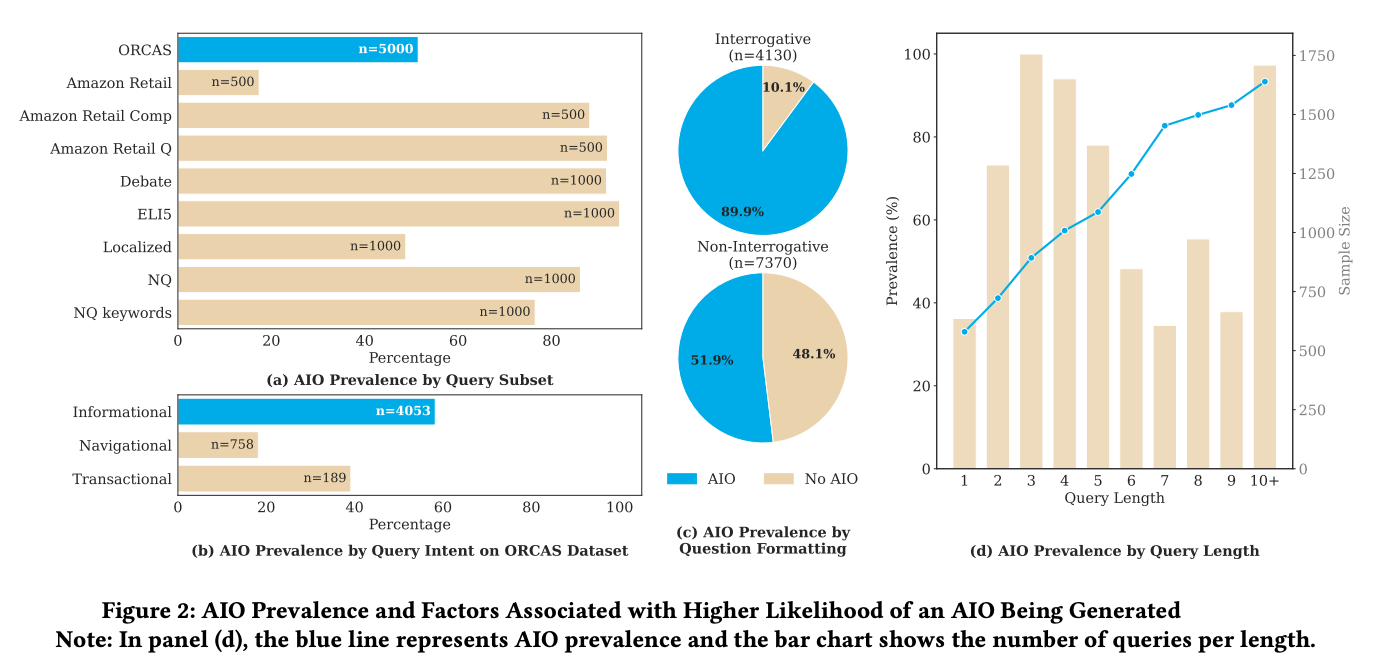
AIO는 전체 벤치마크 쿼리의 65.6%에서 생성되는 것으로 나타났습니다. 실제 사용자 쿼리를 가장 잘 대표하는 ORCAS 데이터셋에서는 51.5%의 쿼리에 AIO가 생성됐습니다. 카테고리별로는 ELI5 쿼리의 94.6%에서 AIO가 생성된 반면, Amazon Retail 쿼리에서는 17.4%에 그쳐 쿼리 유형에 따른 편차가 큰 것으로 확인됐습니다.
AIO 생성 빈도는 쿼리의 의도, 형식, 길이에 따라서도 달라졌습니다. 정보 탐색형(informational) 쿼리에서 AIO 생성 빈도가 가장 높았으며, 의문문 형식의 쿼리(interrogative queries)는 비의문문 쿼리에 비해 AIO가 생성될 가능성이 통계적으로 유의미하게 높았습니다(χ²(1, N=11,500)=1,685.7, p<0.001). 또한 쿼리 길이가 길수록 AIO 생성 빈도가 높아지는 경향도 확인됐습니다. 이는 사용자가 "피자 스톤"처럼 광범위한 키워드보다 "피자 스톤을 어떻게 세척하나요?"처럼 구체적인 정보를 요청할 때 AIO가 더 자주 등장한다는 것을 의미합니다.
주요 발견 2: 세 검색 엔진, 출처 유사도 10~18%에 불과
세 검색 엔진이 제시하는 출처 목록은 서로 크게 다른 것으로 나타났습니다. 아래 표는 구글 AI 오버뷰(AIO), 전통적 구글 검색 결과(SERP), 제미나이 2.5 플래시(GEM) 간 평균 유사도를 보여줍니다.
| 쿼리 카테고리 | Jaccard AIO-SERP | Jaccard AIO-GEM | Jaccard GEM-SERP | RBO AIO-SERP | RBO AIO-GEM | RBO GEM-SERP |
|---|---|---|---|---|---|---|
| ORCAS | 0.17 | 0.12 | 0.20 | 0.24 | 0.17 | 0.26 |
| Amazon Retail | 0.08 | 0.06 | 0.08 | 0.12 | 0.10 | 0.10 |
| Retail-Comp | 0.11 | 0.08 | 0.08 | 0.15 | 0.10 | 0.10 |
| Retail-Q | 0.12 | 0.10 | 0.10 | 0.16 | 0.14 | 0.13 |
| Debate | 0.24 | 0.10 | 0.11 | 0.27 | 0.12 | 0.14 |
| ELI5 | 0.21 | 0.11 | 0.14 | 0.25 | 0.15 | 0.18 |
| Localized | 0.14 | 0.07 | 0.16 | 0.17 | 0.10 | 0.21 |
| NQ | 0.19 | 0.13 | 0.19 | 0.24 | 0.17 | 0.26 |
| NQ Keywords | 0.19 | 0.13 | 0.20 | 0.24 | 0.16 | 0.26 |
| 전체 | 0.18 | 0.11 | 0.16 | 0.23 | 0.15 | 0.21 |
평균적으로 AIO와 전통적 SERP가 공통으로 검색하는 출처는 전체의 18%에 불과했습니다. 주목할 만한 점은 AIO가 경량 제미나이 모델을 기반으로 구축됐음에도 불구하고, AIO와 제미나이의 출처 목록이 가장 낮은 유사도(자카드 0.11, RBO 0.15)를 보였다는 것입니다. 연구진은 이러한 차이가 각 검색 엔진이 검색하는 출처 수의 차이(제미나이 평균 9.68개, AIO 9.24개, 전통적 SERP 8.75개)보다는 각 엔진의 방법론적 차이에서 비롯된 것이라고 분석했습니다.
주요 발견 3: 생성형 검색, 대형·공신력 사이트 외면하고 틈새 사이트 선호
생성형 검색 엔진은 전통적 검색에 비해 인기 있는 웹사이트, 교육·정부 기관, 구글 AI 봇을 차단한 웹사이트의 출처를 인용할 가능성이 통계적으로 유의미하게 낮은 것으로 나타났습니다. 반면 구글 소유 웹사이트의 콘텐츠는 더 많이 인용하는 경향을 보였습니다.
웹사이트 인기도를 측정하는 트랑코(Tranco) 순위 분석에 따르면, 구글 전통 검색은 상위 1,000개 도메인에서 전체 출처의 37.8%를 가져온 반면, AIO는 36.5%, 제미나이는 27.9%에 그쳤습니다. 상위 1위 출처만을 기준으로 하면 이 격차는 더욱 벌어져, 전통적 SERP는 52.7%의 쿼리에서 상위 1,000개 도메인을 인용했지만, AIO는 40.0%, 제미나이는 32.6%에 머물렀습니다. 이는 전통적 검색이 출처의 명성과 인기도를 더 중요하게 반영한다는 것을 시사합니다.
또한 연구진은 구글 검색과 AIO 모두에서 최소 20개의 고유 쿼리에 대해 검색되는 인기 출판사 21곳이 제미나이에서는 한 번도 인용되지 않았다는 사실을 발견했습니다. 뉴욕타임스(NYTimes), ESPN, CNN, BBC, 사이언스다이렉트(ScienceDirect), 로이터(Reuters), 와이어드(WIRED), 네이처(Nature), NBC 뉴스 등이 포함된 이들 출판사는 모두 robots.txt 파일에서 구글 익스텐디드(Google-Extended) 봇을 차단하고 있었습니다. 구글은 이 봇을 차단하면 미래 제미나이 모델 학습이나 응답 그라운딩(grounding)에 해당 콘텐츠가 사용되지 않는다고 밝히고 있으며, 구글 검색 순위에는 영향을 미치지 않는다고 설명합니다. 그러나 연구 결과, 이들 웹사이트의 상당수는 AIO에서도 인용 빈도가 낮은 것으로 나타났습니다.
주요 발견 4: 생성형 검색, 일관성도 낮아
생성형 검색 엔진은 전통적 검색에 비해 동일한 쿼리를 반복 실행했을 때의 일관성이 낮고, 기기 유형이나 쿼리 구문의 소폭 변경에도 더 민감하게 반응하는 것으로 확인됐습니다.
| 기기/위치 조건 | Jaccard AIO | Jaccard GEM | Jaccard SERP | RBO AIO | RBO GEM | RBO SERP |
|---|---|---|---|---|---|---|
| 동일 기기·동일 위치 | 0.66 | 0.46 | 0.78 | 0.69 | 0.52 | 0.86 |
| 동일 기기·다른 위치 | 0.64 | - | 0.76 | 0.68 | - | 0.84 |
| 다른 기기·동일 위치 | 0.55 | - | 0.69 | 0.53 | - | 0.79 |
| 다른 기기·다른 위치 | 0.55 | - | 0.67 | 0.53 | - | 0.77 |
모든 비교 조건에서 생성형 검색 엔진은 전통적 구글 검색보다 낮은 일관성을 보였습니다. 특히 기기 유형 변경이 위치 변경보다 일관성에 더 큰 영향을 미쳤으며, AIO는 전통적 SERP보다 기기 변경에 따른 불일치가 더 크게 나타났습니다.
쿼리의 표면적 변형(예: "what is"와 "what's" 간의 축약 변환, 단어 약어 처리, 물음표 추가·삭제)에 대한 내성 분석에서도 AIO가 가장 취약했습니다. 원본 쿼리와 수정된 쿼리의 검색 출처 간 평균 RBO는 AIO가 0.49(동일 쿼리 반복 대비 28.99% 하락), 전통적 SERP가 0.74(13.95% 하락), 제미나이가 0.5(3.85% 하락)로 나타났습니다. 연구진은 AIO가 경량 제미나이 모델을 사용하기 때문에 추론 능력이 낮아 쿼리의 의도보다 키워드에 더 의존하는 경향이 있을 수 있다고 분석했습니다.
주요 발견 5: 고위험 쿼리에서 신뢰도 낮은 출처 의존
생성형 검색이 민주주의와 사회에 미치는 영향이 가장 우려되는 영역은 고위험 쿼리입니다. 연구진은 토론 주제, 정치인 관련 쿼리, 트렌딩 쿼리를 분석했습니다.
토론 주제 쿼리에서 AIO는 94.6%의 높은 생성 빈도를 보였으며, AIO 요약문의 33.4%가 긍정 또는 부정적 응답으로 시작하는 것으로 나타났습니다. 군사 내 로봇 활용 여부, AI의 의료 진단 사용, 육류 소비 제한, 이민법 개혁 등 논쟁적 사안에서 AIO가 특정 입장을 취한다는 것은 주목할 만한 문제입니다. 제미나이도 5.6%의 응답에서 같은 경향을 보였습니다.
정치인 관련 쿼리에서는 AIO가 93.8%의 높은 빈도로 생성됐습니다. 생성형 검색 엔진은 congress.gov 등 정부 공식 자료를 전통적 검색보다 덜 인용했으며, 미디어 바이어스/팩트체크(MBFC) 신뢰도 평가 기준으로 '의문스러운' 등급(중간 또는 낮은 신뢰도)의 출처를 더 많이 인용하는 것으로 나타났습니다. 구체적으로, AIO가 인용한 출처의 11.4%(저신뢰도 0.5%), 제미나이가 인용한 출처의 15.0%(저신뢰도 0.6%)가 의문스러운 신뢰도 등급을 받은 반면, 전통적 검색은 10.6%(저신뢰도 0.2%)에 그쳤습니다. 또한 제미나이는 아동 인터넷 보호법(CIPA)에 따라 공공 시설에서 아동 접근이 제한된 웹사이트의 콘텐츠를 인용할 가능성이 통계적으로 유의미하게 높은 것으로 나타났습니다.
트렌딩 쿼리에서는 AIO 생성 빈도가 8.1%로 낮게 나타났습니다. 그러나 잘못된 정보를 제시한 사례도 발견됐습니다. 권투 경기 당일 "제이크 폴과 앤서니 조슈아 중 누가 이겼나(who won jake paul or anthony joshua)"라는 트렌딩 쿼리에 대해 AIO는 제이크 폴이 승리했다고 잘못 답변했으며, 인용된 여러 출처 중 실제로 제이크 폴의 승리를 주장한 것은 풍자 스포츠 계정의 페이스북 게시물 단 하나뿐이었습니다.
사회적 함의: 사용자·언론사·생태계 모두에 경고등
연구진은 이번 연구 결과가 사용자, 출판사, 검색 생태계 전반에 중요한 함의를 갖는다고 밝혔습니다.
사용자 관점에서는 생성형 AI의 부정확성과 환각(hallucination) 위험으로 인해 주의가 필요하다고 강조했습니다. 특히 논쟁적이고 고위험한 쿼리에 대해서는 규제가 필요할 수 있다고 지적했습니다.
출판사 관점에서는 생성형 검색이 틈새 콘텐츠 제공자에게는 유리하게 작용하는 반면, 대형 출판사에는 불리하게 작용할 것이라는 분석이 나왔습니다. 연구진은 GEO 기법의 효과에도 의문을 제기했습니다. 제미나이와 AIO의 출처 목록이 가장 낮은 유사도를 보인다는 점에서 복수의 생성형 검색 엔진에 동시에 최적화하기가 어렵고, AIO의 낮은 일관성으로 인해 고순위 최적화 자체가 신뢰하기 어렵다는 이유에서입니다.
구글 AI 크롤러 차단 결정에 대해서도 재고가 필요하다는 시각이 제시됐습니다. 연구 결과, 구글 AI 크롤러를 차단한 웹사이트는 AIO에서도 인용 빈도가 낮아지는 것으로 나타났기 때문입니다. 구글은 웹사이트가 구글 익스텐디드 봇을 차단해도 전통적 구글 검색 순위에는 영향이 없다고 밝히고 있지만, AIO에서의 가시성 감소는 출판사들이 크롤러 차단 전략을 재검토하게 만드는 요인이 되고 있습니다.
소매·서비스 웹사이트의 경우, AIO는 Amazon Retail 쿼리에서는 17.4%의 낮은 생성 빈도를 보인 반면, 제품 비교 쿼리와 질문형 쿼리에서는 각각 88.2%, 92%의 높은 생성 빈도를 기록했습니다. 이는 생성형 검색이 최종 구매 단계보다 고려·조사 단계에서 더 큰 역할을 한다는 것을 시사합니다.
생태계 지속가능성을 위한 제언
연구진은 생성형 검색의 지속가능한 생태계 구축을 위해 여러 정책적 제언을 내놓았습니다.
먼저, 생성형 검색 엔진의 응답 일관성 개선이 시급하다고 강조했습니다. 동일한 의도의 쿼리에 대해 다른 사용자가 다른 정보를 받는 것은 민주주의에 심각한 위협이 될 수 있다는 이유에서입니다.
또한 논쟁적 사안이나 고위험 주제(예: 선출직 공무원 관련 정보, 심각한 의료 증상 식별)에 생성형 검색 엔진을 활용하는 것을 규제하는 정책 마련이 필요하다고 촉구했습니다.
가장 근본적인 제언은 디지털 출판사와 AI 기업 간의 수익 프레임워크 구축입니다. 연구진은 트래픽 감소로 인한 광고 수익 하락이 언론출판사의 존립을 위협하고, 이는 결국 고품질 콘텐츠의 소멸로 이어져 생성형 검색 엔진 자체도 학습과 그라운딩에 필요한 콘텐츠를 잃게 되는 악순환을 초래할 것이라고 경고했습니다. 협상을 통한 라이선싱, 크롤링당 과금, 수익 공유 등의 방식으로 출판사와 생성형 검색 제공업체 간의 인센티브를 일치시켜야 양측이 모두 이익을 얻는 지속가능한 생태계를 구축할 수 있다는 것이 연구진의 주장입니다.
한계와 향후 과제
이번 연구는 몇 가지 한계를 지니고 있습니다. 먼저, 검색 업계에서의 지배적 위치를 고려해 구글에만 초점을 맞췄기 때문에 챗GPT, 퍼플렉시티 AI(Perplexity AI), 빙 코파일럿(Bing Copilot) 등 다른 생성형 검색 도구로의 일반화에는 한계가 있습니다. 또한 API를 통한 대규모 데이터 수집 방식으로 인해 기기 유형과 도시 이외의 사용자 특성에 따른 결과 변화를 연구하기 어려웠습니다. 아울러 분석이 특정 시점의 단면적 데이터에 기반한다는 점도 한계로 지적됩니다.
연구진은 생성형 검색의 진화와 지속가능성에 관한 향후 연구를 지원하기 위해 처리된 데이터셋과 코드를 공개했습니다. 이번 연구는 미국 국립과학재단(NSF) 보조금(CNS2237328), 국립보건원(NIH) 산하 국립 중개과학발전센터 지원금(UM1TR004789), 마틴 투크만 기금, 레이어 재단의 지원을 받아 수행됐습니다.
참고 문헌
- Grossman, R., Liu, S., Chen, M. K., Smith, M., Borcea, C., & Chen, Y. (2026). How Generative AI Disrupts Search: An Empirical Study of Google Search, Gemini, and AI Overviews. arXiv preprint arXiv:2604.27790.