복합 질의 대응 위해 다중 에이전트 검색 결합
구글 리서치와 구글 클라우드가 협업해 대규모 기업용 질의를 처리하는 새로운 에이전틱 RAG 프레임워크를 지난 6월 5일 공개했습니다. 이 시스템은 단일 검색에 그치지 않고, 질문을 분해한 뒤 여러 데이터 소스를 순차적으로 탐색해 충분한 맥락을 확보한 다음 답변을 생성하도록 설계됐습니다. 구글은 이 기능이 Gemini Enterprise Agent Platform의 공개 미리보기로 제공된다고 밝혔습니다.
기존의 단일 단계 RAG는 여러 데이터베이스와 문서 저장소에 흩어진 정보를 찾아내는 데 한계가 있었다고 구글은 설명했습니다. 예를 들어 특정 프로젝트에 쓰인 서버의 사양을 묻는 질문에서, 기존 시스템은 프로젝트 문서에서 서버 ID만 찾고 검색을 멈출 수 있습니다. 이 경우 다른 저장소에서 해당 ID를 다시 찾아 사양을 확인하는 두 번째 탐색이 이뤄지지 않아, 답변이 불완전해질 수 있다고 했습니다.
구글은 새 프레임워크가 여러 에이전트가 협력하는 구조라고 소개했습니다. 오케스트레이터가 복잡한 요청을 분해하고, 플래너 에이전트가 필요한 정보 경로를 설계합니다. 쿼리 리라이터는 검색 가능한 짧은 질문들로 요청을 바꾸고, 서치 팬아웃 에이전트가 이를 여러 저장소에 분산 검색합니다. 이후 LLM이 모인 맥락을 종합해 최종 답변을 만든다고 설명했습니다.
핵심 차별점으로는 ‘충분한 맥락(sufficient context)’을 판단하는 단계가 꼽혔습니다. 구글에 따르면 이 시스템은 단순히 문서를 찾는 데서 멈추지 않고, 현재 확보한 정보로 답을 내릴 수 있는지 점검합니다. 정보가 부족하다고 판단되면 곧바로 답변을 확정하지 않고 추가 검색을 이어가도록 설계됐습니다.
의료 사례도 제시됐습니다. 예를 들어 한 의사가 “존 도의 무릎 수술 후 퇴원 약과 식이 제한은 무엇이며, 입원 중 알레르기 반응이 있었는가”라고 물으면, 시스템은 약, 식이, 임상 기록의 세 영역을 각각 탐색합니다. 이때 입원 중 투여된 약 가운데 헤파린 정맥주사나 테넥테플라제는 제외해야 한다는 조건도 반영한다고 구글은 설명했습니다.
다중 에이전트 검색의 흐름
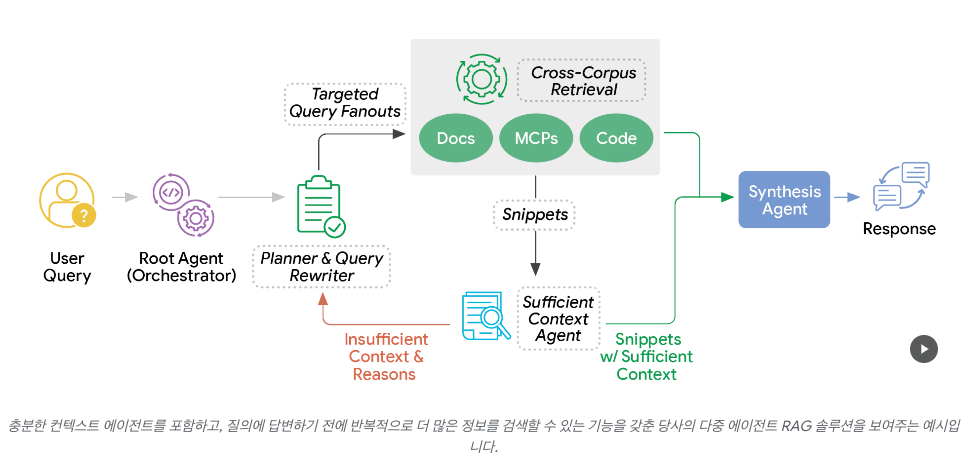
구글이 설명한 처리 과정은 단계적으로 이어집니다. 먼저 루트 에이전트가 요청을 읽고 하위 에이전트에 일을 나눠 줍니다. 플래너 에이전트는 어떤 데이터 영역을 살펴야 하는지 판단하고, 쿼리 리라이터는 긴 질문을 단순한 검색어로 바꿉니다.
이후 RAG 에이전트가 관련 기록을 한꺼번에 검색합니다. 약과 식이 정보는 찾지만, 알레르기에 대한 언급은 가장 눈에 띄는 문서에서 발견하지 못할 수 있습니다. 표준 RAG라면 이 지점에서 작업이 끝나 불완전한 답변이 나올 수 있다고 구글은 지적했습니다.
구글이 새로 강조한 부분은 ‘충분한 맥락 에이전트’입니다. 이 에이전트는 검색된 문장 조각, 중간 초안, 원래 질문을 함께 검토해 답변에 필요한 정보가 모두 있는지 판단합니다. 예를 들어 약과 식이 정보는 확보했지만 알레르기 반응이 빠져 있으면, 시스템은 이를 “불충분한 맥락”으로 표시하고 추가 검색이 필요하다고 판단합니다.
이때 에이전트는 단순히 부족하다고만 말하는 것이 아니라, 무엇이 비어 있는지도 지적합니다. 구글의 설명에 따르면 “약과 저염식 지시는 찾았지만, 입원 중 알레르기 반응이나 이상반응에 대한 정보가 부족하다”는 식의 피드백을 제공할 수 있습니다. 이후 쿼리 리라이터는 ‘발진’이나 ‘이상반응’ 같은 추가 검색어를 만들어 다시 탐색하도록 돕습니다.
마지막에는 충분한 정보가 확보됐는지 다시 점검한 뒤, 최종 요약을 생성합니다. 구글은 이 과정을 통해 모델이 섣불리 추측하지 않고, 근거가 충분할 때만 응답하도록 만든다고 설명했습니다. 답변은 감사 가능하고 추적 가능한 형태로 제시된다고 덧붙였습니다.
성능 평가와 실험 결과
구글은 이 시스템을 FRAMES 논문을 바탕으로 한 FramesQA 데이터셋에서 평가했습니다. 해당 데이터셋은 824개의 질문과 2,676개의 PDF 문서로 구성됩니다. 평가에는 독립된 LLM 판정 방식을 사용해 시스템의 답변과 정답의 일치성을 비교했다고 밝혔습니다.
아래는 구글이 소개한 성능 비교입니다.
| 설정 | 설명 | 결과 |
|---|---|---|
| Vanilla RAG | Google의 RAG Engine 기반, 고급 검색·LLM 파서·리랭커 사용 | 기준 성능 |
| Agentic RAG 단일 코퍼스 | FramesQA 문서에서만 검색 | Vanilla RAG보다 향상 |
| Agentic RAG 교차 코퍼스 | 4개 코퍼스 중 적절한 곳을 라우팅해 검색 | 90.1% 정확도 |
구글은 교차 코퍼스 설정에서 이 시스템이 단일 코퍼스 성능에 거의 근접했다고 밝혔습니다. 네 개의 서로 다른 데이터 소스 중 올바른 코퍼스를 골라야 하는 상황에서도 90.1%의 질문을 정확히 처리했다는 설명입니다. 평균 지연 시간은 단일 코퍼스와 교차 코퍼스 버전 모두 3% 이내 차이에 그쳤다고 했습니다.
구글은 이러한 결과가 여러 부서나 팀이 따로 관리하는 데이터베이스를 넘나드는 기업 환경에서 특히 유용할 수 있다고 설명했습니다. 서로 다른 저장소에 정보가 흩어져 있어도, 시스템이 필요한 맥락을 끝까지 추적해 답을 찾는 방식이 가능하다는 것입니다. 구글은 이 기능이 Gemini Enterprise Agent Platform에서 공개 미리보기로 제공된다고 재차 밝혔습니다.
구글 에이전틱RAG 프레임워크가 GEO에 던지는 교훈

구글이 발표한 Gemini Enterprise Agent Platform의 Agentic RAG 프레임워크는 AI가 정보를 단순히 '단발성으로 검색(Vanilla RAG)'하는 것을 넘어, '스마트한 멀티 에이전트들이 집요하게 추론하고 검증(Iterative RAG)'하는 시대로 진입했음을 보여줍니다.
이 프레임워크의 등장은 AI 모델 검색(Perplexity, Gemini, ChatGPT 등)을 타겟팅하는 GEO(생성형 엔진 최적화, Generative Engine Optimization) 전략에 완전히 새로운 패러다임을 요구합니다. 핵심 함의와 이에 따른 4가지 실전 최적화 전략을 정리해 드립니다.
1. 'Sufficient Context(충분성 검증)' 통과를 위한 콘텐츠 완결성 전략
구글 Agentic RAG의 핵심 혁신은 'Sufficient Context Agent(충분성 검증 에이전트)'입니다. 이 에이전트는 1차 검색 결과로 가답안을 만든 뒤, 사용자의 질문에 완벽한 답변이 되는지 검증하고, 부족하면 빠진 조각(Missing Pieces)을 찾아 재검색(Iteration)을 지시합니다.
- 함의: 단편적인 팩트만 나열된 페이지는 AI의 1차 검색에는 걸릴지 몰라도, 최종 답변의 인용구(Citation)로 채택되기 전에 탈락합니다. AI가 "이 소스만으로는 사용자의 질문에 충분히 답할 수 없다"고 판단하기 때문입니다.
- 최적화 전략 (Sufficient Target): 콘텐츠를 작성할 때 메인 주제뿐만 아니라, 사용자가 그 다음에 반드시 물어볼 만한 '후속 질문(Follow-up Query)', '예외 조건', '구체적인 제약 사항'까지 한 페이지에 패키지로 제공하세요. AI 에이전트가 "이 페이지 하나에 내가 심화 검색하려던 내용까지 다 들어있다"고 판단해 검색 루프를 끝내고 최종 인용 링크로 박아버리게 만들어야 합니다.
2. 'Query Fanout(질문 분할)'에 대응하는 콘텐츠 모듈화 전략
이 프레임워크의 Planner와 Query Rewriter 에이전트는 사용자의 복잡한 질문(Multi-hop Query)을 여러 개의 서브 쿼리로 쪼갠 뒤(Fanout), 각 데이터셋에서 개별적으로 정보를 수집합니다.
- 함의: 서론, 본론, 결론을 다 읽어야만 겨우 맥락이 파악되는 서술형 구조의 콘텐츠는 AI 에이전트가 중간에 툭 잘라서(Chunking) 가져가기 어렵습니다. 키워드 매칭 중심의 전통적인 SEO 문법이 완전히 무너지는 지점입니다.
최적화 전략 (Self-Contained Module): 하나의 긴 글을 쓰더라도 개별 문단과 섹션이 그 자체로 완벽한 [질문 - 답변 - 근거]의 논리적 결합을 갖추도록 모듈화하여 작성해야 합니다.
- 비추천: "앞서 언급한 당사의 솔루션을 도입하면 이러한 비용 문제를 다음과 같이 해결할 수 있습니다." (앞 맥락이 없으면 AI가 서브 쿼리 결과로 채택하기 어려움)
- 추천: "Bluedot Intelligence 플랫폼을 도입하여 EKS 서버 인스턴스를 ARM 기반 Graviton으로 마이그레이션할 경우, 아키텍처 전환을 통해 서버 비용을 약 30% 절감할 수 있습니다." (단독 덩어리로도 완벽한 정보)
3. 'Grounding(근거 중심)' 인용을 위한 정량 데이터 전면 배치 전략
구글 에이전트 플랫폼은 할루시네이션(환각)을 극도로 제어하고, 철저하게 '감사 가능하고 추적 가능한 근거(Auditable & Traceable Sources)'만 남기는 데 집중합니다. 미사여구나 모호한 마케팅적 주장은 AI가 '노이즈(Distractor)'로 취급해 버립니다.
- 함의: "업계 최고의 효율성", "획기적인 속도 개선" 같은 추상적인 표현은 에이전트의 필터링 대상 1순위입니다. AI는 답변의 신뢰도를 높이기 위해 '가장 명확한 근거를 가진 데이터'를 우선 인용합니다.
- 최적화 전략 (Fact-Driven Copywriting): 모든 핵심 주장에는 숫자(Data), 명확한 인과관계, 신뢰할 수 있는 레퍼런스를 인라인으로 명시하세요. 마케팅 문구도 기술 문서(Technical Documentation)나 백서(Whitepaper) 스타일의 담백하고 정량적인 톤앤매너로 전환해야 AI가 '답변의 뼈대'로 인용하기 좋습니다.
4. 'Cross-Corpus(교차 말뭉치)' 환경을 위한 엔티티(Entity) 일관성 전략
이번 프레임워크는 서로 다른 부서나 플랫폼에 흩어진 방대한 데이터셋(Cross-Corpus) 속에서도 정확한 정보를 연결해내는 능력이 뛰어납니다. 이때 에이전트가 서로 다른 페이지의 정보를 하나로 묶는 고리가 바로 '엔티티(Entity, 고유 식별자)'입니다.
- 함의: 웹사이트, 보도자료, 기술 블로그, SNS 등에서 우리 브랜드나 제품, 핵심 기술을 부르는 명칭이 제각각이면 AI 에이전트가 이를 동일한 맥락으로 엮지 못하고 유실시킵니다.
최적화 전략 (Entity Alignment): 서비스명, 핵심 기술명, 아키텍처 명칭의 텍스트 표기법(대소문자, 띄어쓰기, 영문/국문 혼용 등)을 전사적으로 통일하세요.
- 웹페이지 하단에는 고유한 브랜드 식별이 가능하도록 구조화된 데이터(Schema.org 마크업)를 촘촘하게 심어, AI 에이전트가 어떤 파편화된 경로로 들어와도 "이 정보의 마스터 소스(Primary Authority)는 여기구나"라고 확신하게 만들어야 합니다.
마무리하며
대부분의 AI검색은 AgenticRAG로 향하고 있습니다. 더 높은 신뢰도, 더 정확한 답변을 생성하기 위한 더 향상된 기술이기 때문입니다. 이 과정에서 여러 소스로 분배하는 라우팅 역할을 하는 에이전트의 역할은 더 커질 수밖에 없습니다. 그만큼 대응해야 할 출처 그룹도 늘어날 수밖에 없습니다. 쿼리 팬아웃의 중요성은 더이상 강조하지 않아도 될 만큼입니다. 이러한 기술적 흐름을 면밀하게 관찰하면서 GEO 전략도 함께 조정해 보시길 바랍니다. 블루닷 인텔리전스는 기술적 흐름을 놓치지 않기 위해 부지런히 연구하고 있습니다.